KNN算法
KNN(K-NearestNeighbor)算法既可以用于分类,也可用于回归。这里介绍他的分类用法。
训练集:一堆拥有标签的m维数据,可以表示为: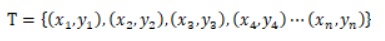
其中, 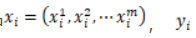 是标签,即所属类别。
是标签,即所属类别。
目标:一个测试数据x,预测其所属类别。
算法:
1、计算测试点x与训练集中每一个数据的“距离”
2、将所求的距离进行升序排序,选择前K个
3、在上一步中所得到的K个数据中,根据决策规则(如多数表决)决定x的类别预测结果
1、“距离”是啥距离?
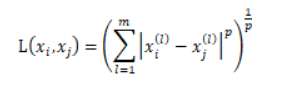
上式表示的是:m维数据与的距离就是这么求的。
当p=2时,这个距离就称为欧式距离,是不是很熟悉?
当p=1时,称为曼哈顿距离
根据数据特性的不同,我们可以选择不同的距离来度量。
2、K值如何选择
我们一直在谈KNN,那这个K我们该如何选择呢?
K值太小,预测结果会对近邻的训练数据十分敏感,模型过于复杂,易发生过拟合
K值太大,会导致分类结果模糊,模型过于简单。
对于k值的选择有这么几种方法:交叉验证、贝叶斯方法、bootstrap。
一般是取个较小值,采用交叉验证法来选取最优的K值。
3、决策规则是啥?
一般是选用多数表决规则,即在K个数据中,哪种类别出现的次数最多,这个类别就是x的预测类别。
kd树
上面说的是计算测试点和训练集中的每一个数据的距离,然后进行排序。数据量少的时候完全问题,可是当数据量大的时候,臣妾做不到啊!!!
这时候,我们聪明的前辈就提出了kd树(k-dimensional tree)。这是一颗什么样的树呢?
kd树可以帮助我们在很快地找到与测试点最邻近的K个训练点。不再需要计算测试点和训练集中的每一个数据的距离。
kd树是二叉树的一种,是对k维空间的一种分割,不断地用垂直于坐标轴的超平面将k维空间切分,形成k维超矩形区域,kd树的每一个结点对应于一个k维超矩形区域。
kd树的构造

我们有二维数据集
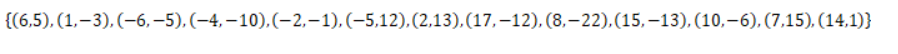
将他们在坐标系中表示如下:
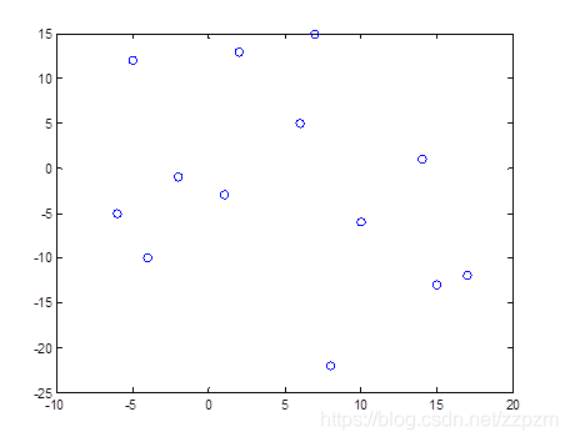
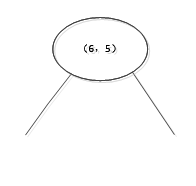
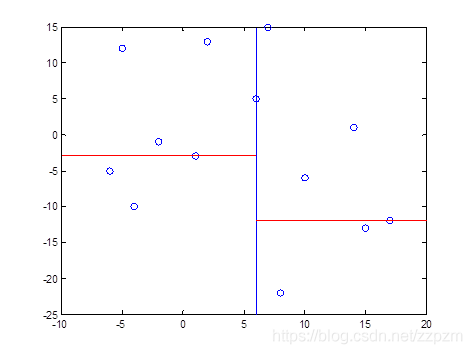
开始:选择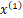 为坐标轴,中位数为6,即(6,5)为切分点,切分整个区域
为坐标轴,中位数为6,即(6,5)为切分点,切分整个区域
再次划分区域
以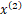 为坐标轴,选择中位数,可知左边区域为-3,右边区域为-12。所以左边区域切分点为(1,-3),右边区域切分点坐标为(17,-12)
为坐标轴,选择中位数,可知左边区域为-3,右边区域为-12。所以左边区域切分点为(1,-3),右边区域切分点坐标为(17,-12)
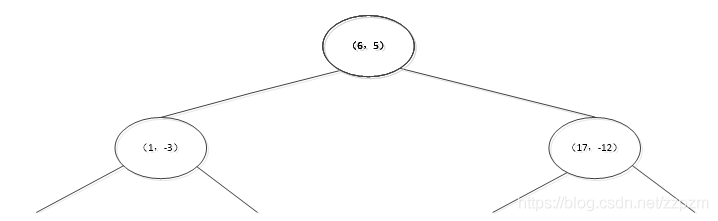
再次对区域进行切分,同上步,我们可以得到切分点,切分结果如下:
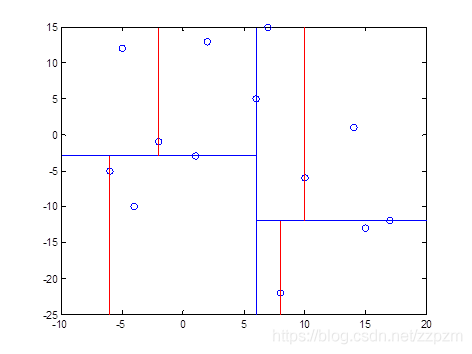
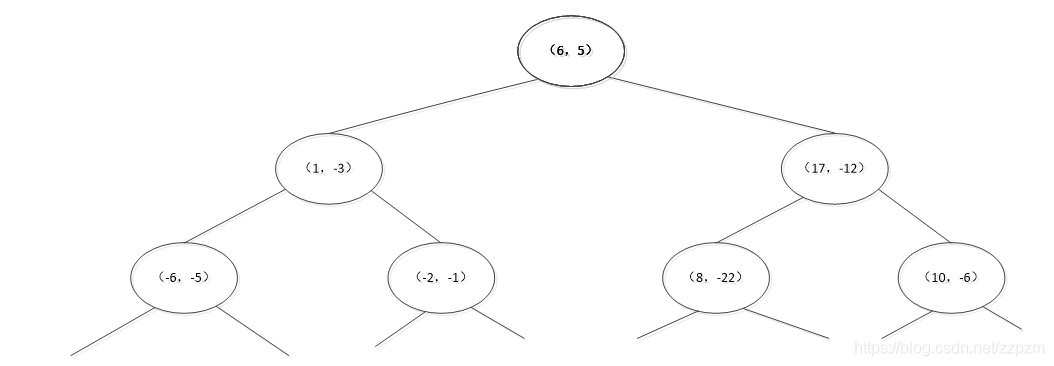
最后分割的小区域内只剩下一个点或者没有点。我们得到最终的kd树如下图
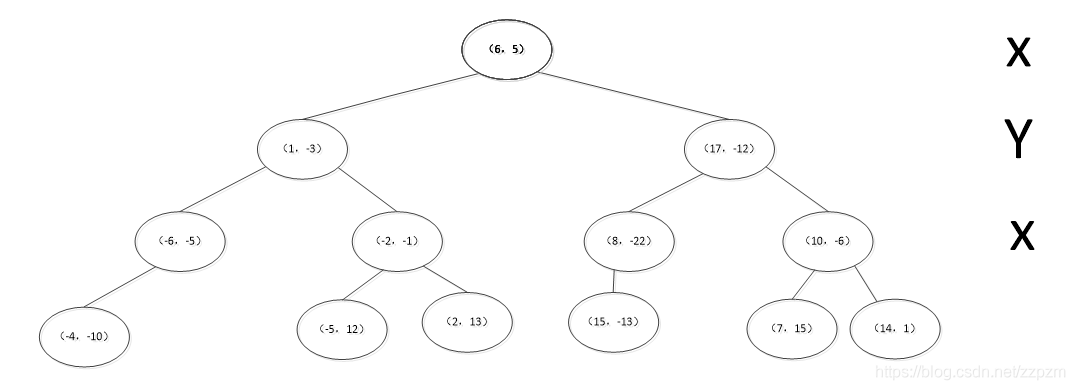
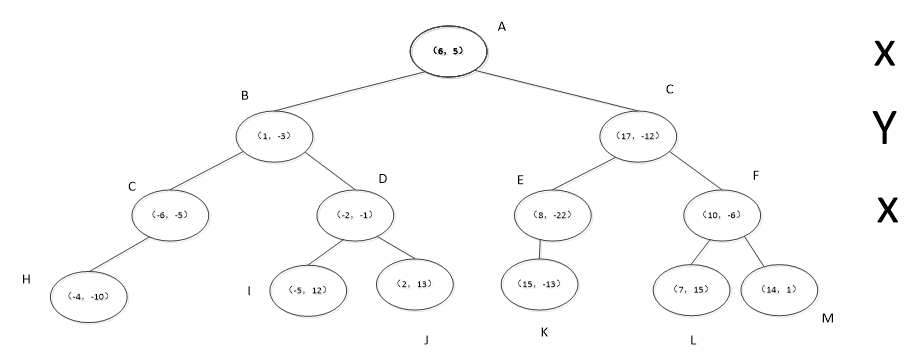
kd树完成K近邻的搜索
我们现在就计算p(-1,-5)的3个邻近点。
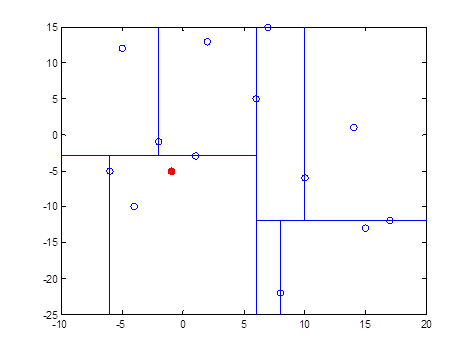
我们拿着(-1,-5)寻找kd树的叶子结点。
得到p点的3个邻近点,为(-6,-5)、(1,-3)、(-2,-1)
决策树
决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
决策树是一种十分常用的分类方法,需要监管学习(有教师的Supervised Learning),监管学习就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
决策树的生成主要分以下两步,这两步通常通过学习已经知道分类结果的样本来实现。
节点的分裂:一般当一个节点所代表的属性无法给出判断时,则选择将这一节点分成2个子节点(如不是二叉树的情况会分成n个子节点)
阈值的确定:选择适当的阈值使得分类错误率最小 (Training Error)。
分类
比较常用的决策树有ID3,C4.5和CART(Classification And Regression Tree),CART的分类效果一般优于其他决策树。
- ID3: 由增熵(Entropy)原理来决定那个做父节点,那个节点需要分裂。对于一组数据,熵越小说明分类结果越好。
- C4.5:通过对ID3的学习,可以知道ID3存在一个问题,那就是越细小的分割分类错误率越小,所以ID3会越分越细,比如以第一个属性为例:设阈值小于70可将样本分为2组,但是分错了1个。如果设阈值小于70,再加上阈值等于95,那么分错率降到了0,但是这种分割显然只对训练数据有用,对于新的数据没有意义,这就是所说的过度学习(Overfitting)
- CART:分类回归树,,CART只能将一个父节点分为2个子节点。CART用GINI指数来决定如何分裂:GINI指数:总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)。

ps:以上的决策树训练的时候,一般会采取Cross-Validation法:比如一共有10组数据:
第一次. 1到9做训练数据, 10做测试数据
第二次. 2到10做训练数据,1做测试数据
第三次. 1,3到10做训练数据,2做测试数据,以此类推
做10次,然后大平均错误率。这样称为 10 folds Cross-Validation。
比如 3 folds Cross-Validation 指的是数据分3份,2份做训练,1份做测试。



