1、前言
DB:(database,数据库,数据库实际上在硬盘上以文件的形式存在)
DBMS(database management system(数据库管理系统)常见的有MySQL、Oracle、DB2等等)
SQL:结构化查询语句,便准通用的语言。高级语言,实际上内部先进性编译,在执行sql(sql由DBMS进行编译)
PS:DNMS负责执行sql语句,通过sql语句管理DB中的数据;执行不区分大小写;
2、什么是表?
表:table
表:table是数据库的基本组成单元,所有的数据都以表格形式组织,目的是具有可读性
表包括行(数据/记录data)和列(字段column)
3、sql语句分类
DQL(数据查询语言):查询语句
DML(数据操作语言):insert、delet、update对表中的数据增删改语句
DDL(数据定义语言):creat、drop、alter对表结构的增删改
TCL(事务控制语言):commit提交事务,rollback回滚事务(traction)
DCL(数据控制语言):grant授权、revoke撤销权限等
4、导入数据
第一步:登录mysql -uroot -p
第二步:查看有哪些数据库
show database;(mysql命令)
第三步:创建数据库
creat database bjpowernode;(mysql命令)
第四步:使用bjpowernode数据库
use bjpowernode;(mysql命令)
第五步:查看当前使用的数据库中有哪些表
show tables;(mysql命令)
第六步:初始化命令
source C:\Users\29854\Desktop\resources\bjpowernode.sql
以sql结尾的文件叫sql脚本
当一个文件的扩展名是.sql,并且文件中编写了大量的sql语句,称为sql脚本
PS:像批量执行SQL语句,用source命令完成初始化
5、基本命令
1、删除数据库:drop database bj;
2、查看表的结构:desc 表名;
3、表中的数据:select * from dept;
4、常用命令select database();select version();\c;结束一条语句
5、查看创建表时的语句:show create table emp;
6、简单的查询语句:
select 字段名1,2,3,... from 表名;
PS:
1、任何一条语句以“;”结尾
2、sql语句不区分大小写
3、字段可以参加数学运算
4、给查询结果的列重命名 select ename , sal12 as yearsal from emp; select ename , sal12 as ‘年薪’ from emp;
5、sql语句中字符串用单引号括起来
6、设置MySQL密码的不同姿势
0x01 用SET PASSWORD命令
首先登录MySQL。
1 | 格式:mysql> set password for 用户名@localhost = password('新密码'); |
0x02 用mysqladmin
1 | 格式:mysqladmin -u用户名 -p旧密码 password 新密码 |
0x03 用UPDATE直接编辑user表
首先登录MySQL。
1 | mysql> use mysql; |
0x04 使用GRANT语句
1 | mysql>grant all on *.* to 'root'@'localhost' IDENTIFIED BY '你的密码'with grant option ; |
0x05 在忘记root密码或初始化密码的时候
1 | 以windows为例: |
7、条件查询
语法格式:select 字段 from 表名 where 条件;
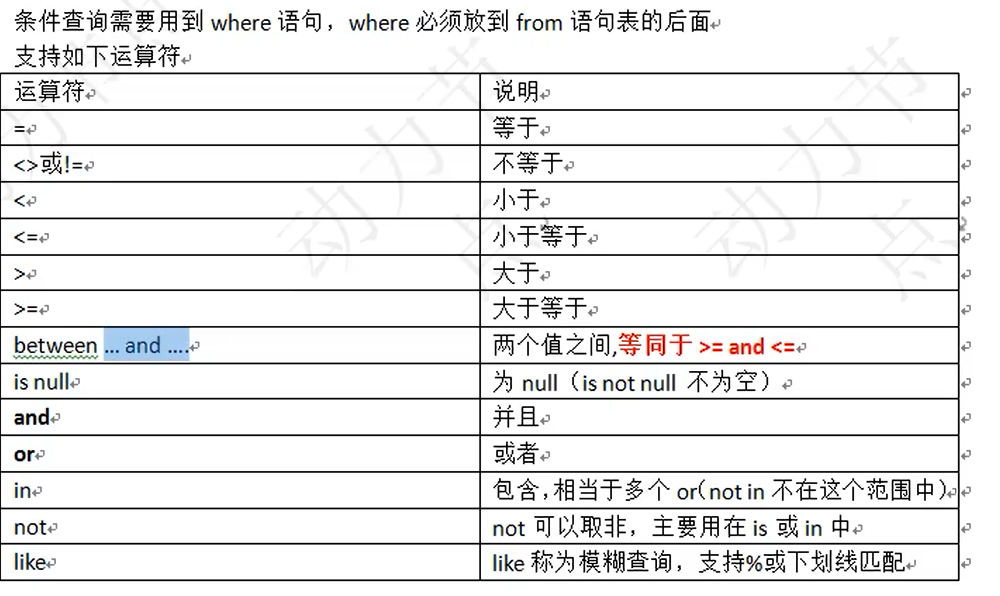
1 | select ename from emp where sal = 5000; |
找出那些人没有津贴。null在数据库中不是一个值,代表什么也没有,为空,必须使用is null或者is not null
1 | select ename,sal,comm from emp where comm is null; |
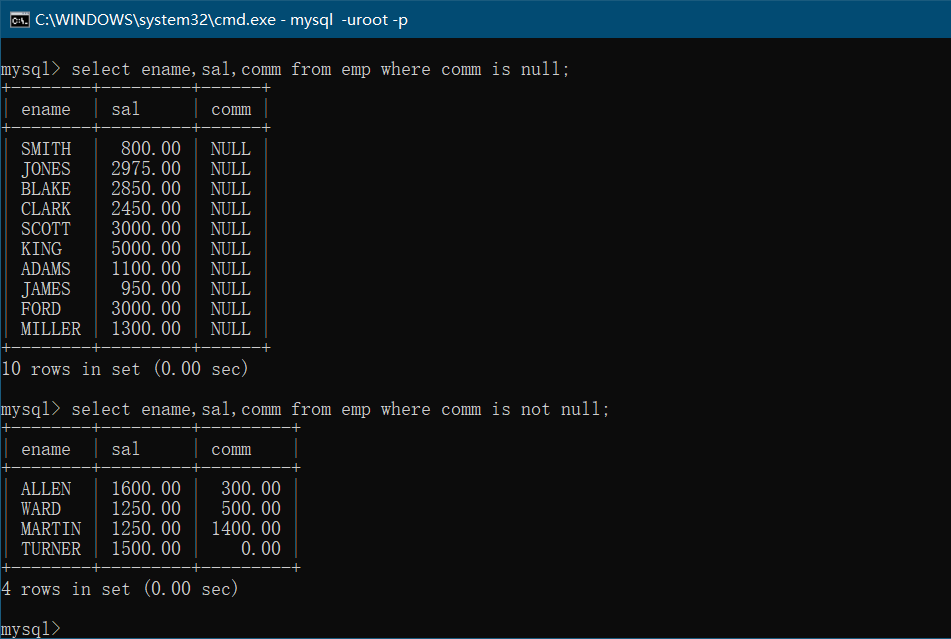
- and和or一起用
1
2select ename,sal,deptno from emp where sal > 1000 and deptno = 20 or deptno = 30;
select ename,sal,deptno from emp where sal > 1000 and (deptno = 20 or deptno = 30);
注意优先级的顺序,and>or;以后优先级的顺序不确定的时候直接使用小括号
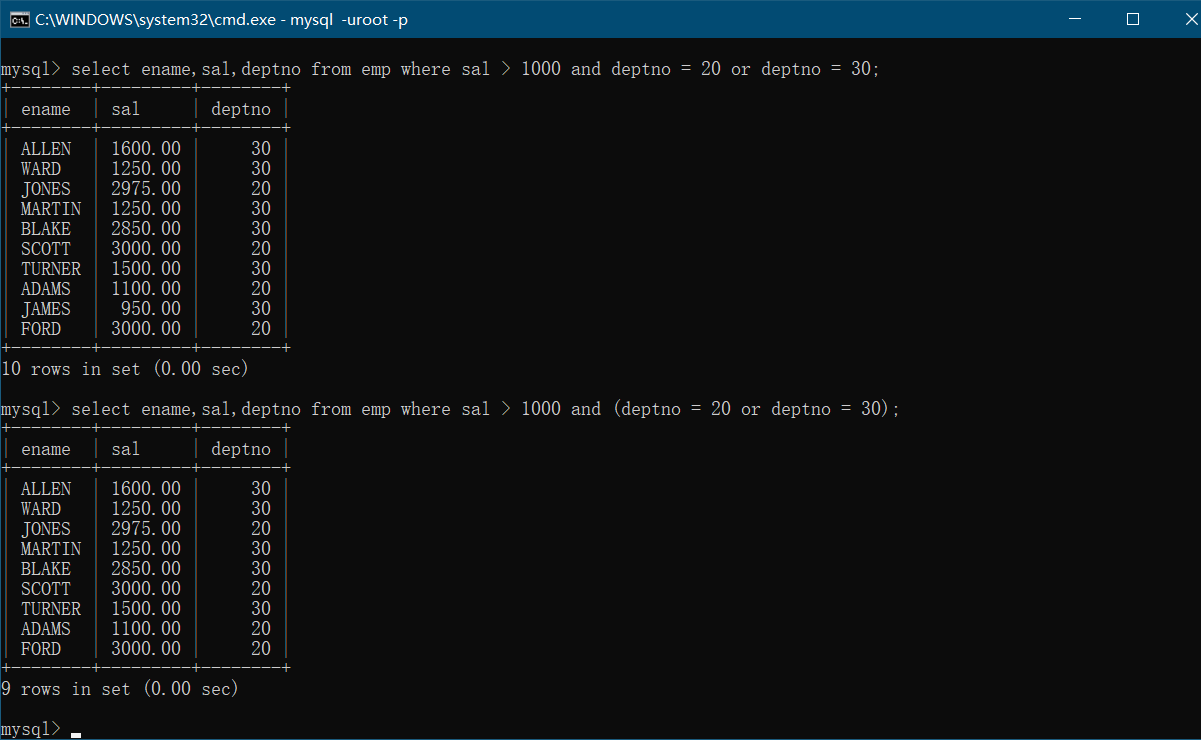
- in等同于or:
1
2
3select ename,job from emp where job = 'MANAGER' or job = 'salesman';
select ename,job from emp where job in ('manager','salesman');
PS:in里边的变量不是区间select ename,job from emp where job in (100,200);
not in
模糊查询like
找出名字中当中有o的(在模糊查询中掌握两个特殊符号,一个是%,一个是_)
%代表任意多个字符,_代表任意一个字符
1 | //找出名字中第二个字母是A的 |
8、排序和分组函数
升序、降序
1 | select ename,sal from emp order by sal;//默认升序 |
分组函数(多行处理函数【输入多行输出一行】)
1 | //所有的分组函数都是对“某一组“数据进行操作,一共5个 |
分组函数自动忽略空值(null),不需要手动加where条件排除空值
select count(ename) from emp;
select count(*) from emp;
select sum(sal) from emp;
select max(sal) from emp;
select min(sal) from emp;
select avg(sal) from emp;
一切数据库规定,只要有null参与的运算,结果一定是null
ifnull(可能为null的数据,被当作什么处理)//空处理函数if(null,0)
1 | //找出工资水品高于平均薪资的员工 |
- ps:count()和count(具体某个字段)的区别。count()统计总记录条数;count(某个字段)统计字段中不为null的数据总数量。
group by和having
- group by :按照某个字段或者某些字段进行分组;
- having:对分组之后的数据进行再次过滤;
group by
1 | select max(sal) from emp group by job;//找出某个岗位的最高薪资 |
PS:分组函数一般会和group by联合使用,这也是被称为分组函数的原因。任何一个分组函数(count sum avg max min)都是在group by 语句执行结束后才会执行。当一条语句没有group by,整张表数据自成一组。
1 | select job,avg(sal) from emp group by job;//平均工资 |
多个字段能不能联合起来一块分组?
案例:找出每个部门不同工作岗位的最高薪资。
1 | select |
having
找出每个部门的最高薪资,要求显示薪资大于2900的数据。
1 | select max(sal),deptno from emp group by deptno; |
找出每个部门的平均薪资,要求显示薪资大于2000的数据。
第一步:找出每个部门平均工资
select avg(sal),deptno from emp group by deptno;第二步:要求显示薪资大于2000的数据
select avg(sal),deptno from emp group by deptno having avg(sal)>2000;select avg(sal),deptno from emp where avg(sal)>2000 group by deptno ; //错误,where后边不能使用分组函数,只能使用having过滤
PS:having只在有group by时可以使用
9一个完整的DQL语句
1 | select 5 |

去除重复记录
select distinct job from emp; //distinct
PS:只能出现在所有字段的最前方,因为两个字段的数据可能行数不同
select distinct job,deptno from emp; //联合去重
案例:统计岗位的数量
select count(distinct job) from emp;
连接查询
什么是连接查询?
在实际开发中,大部分的情况下啊都不是从但表中查询数据,一般都是多张表联合查询取出最终结果。
在实际开发中,一般一个业务都会对应多张表,比如:学生和班级,起码两张表。
如果存储到一张表中,数据会存在大量的重复,导致数据的冗余。
连接查询分类
- 根据语法出现年代
- SQL92(一些老的DBA可能还在使用这种语法。DBA:database administrator,数据库管理员)
- SQL99(比较新)
- 根据表的连接方式划分
- 内连接:
- 等值连接
- 非等值连接
- 自连接
- 外连接:
- 左外连接(左连接)
- 右外连接(右链接)
- 全连接(很少用)
- 内连接:
在表的链接查询方式有一面现象被称为:笛卡儿积现象(笛卡尔乘积现象)
案例:找出每一个员工的部门名称,要求显示员工名称和部门名称
emp表
+——–+——–+
| ename | deptno |
+——–+——–+
| SMITH | 20 |
| ALLEN | 30 |
| WARD | 30 |
| JONES | 20 |
| MARTIN | 30 |
| BLAKE | 30 |
| CLARK | 10 |
| SCOTT | 20 |
| KING | 10 |
| TURNER | 30 |
| ADAMS | 20 |
| JAMES | 30 |
| FORD | 20 |
| MILLER | 10 |
+——–+——–+
dept表
+——–+————+———-+
| DEPTNO | DNAME | LOC |
+——–+————+———-+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+——–+————+———-+
1 | select ename,dname from emp,dept; //ename和dname要联合起来显示,粘到一块 |
出现笛卡尔积现象,当两张表进行查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积。
关于表的别名:
select e.ename,d.dname from emp e,dept d;表的别名有什么好处?
- 第一:执行效率高
- 第二:可读性好
如何避免笛卡尔积现象?加条件进行过滤。
思考:避免笛卡尔积现象会减少匹配次数嘛?
不会,次数还是那样,只不过减少有效记录。
select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno;//SQL92,以后不用。
内连接之等值连接,最大特点是:条件是等量关系
查询每个员工的部门名称,要求显示员工名和部门名
SQL92:(太老不用)
select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno;
SQL99:(常用)
select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
select e.ename,d.dname from emp e inner join dept d on e.deptno = d.deptno;//inner可以省略,带有inner可读性更强
语法:… A join B on 连接条件 where …
SQL99语法结构更清晰,表的链接条件和后来的where条件分离了。
内连接之非等值连接,最大的特点:连接条件中的关系是非等量关系
?找出每个员工的工资等级,要求显示员工名、工资、工资等级。
mysql> select ename,sal from emp;
+——–+———+
| ename | sal |
+——–+———+
| SMITH | 800.00 |
| ALLEN | 1600.00 |
| WARD | 1250.00 |
| JONES | 2975.00 |
| MARTIN | 1250.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| TURNER | 1500.00 |
| ADAMS | 1100.00 |
| JAMES | 950.00 |
| FORD | 3000.00 |
| MILLER | 1300.00 |
+——–+———+
14 rows in set (0.01 sec)mysql> select * from salgrade;
+——-+——-+——-+
| GRADE | LOSAL | HISAL |
+——-+——-+——-+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+——-+——-+——-+
5 rows in set (0.00 sec)
select e.ename,e.sal,s.grade from emp e inner join salgrade s on e.sal between s.losal and s.hisal;//inner 可以省略
+——–+———+——-+
| ename | sal | grade |
+——–+———+——-+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+——–+———+——-+
14 rows in set (0.01 sec)
自连接:最大的特点就是:一张表看成两张表,自己连接自己
?找出每个员工的上级领导,要求显示员工和对应的领导名。
select empno,ename,mgr from emp;emp a 员工表
+——-+——–+——+
| empno | ename | mgr |
+——-+——–+——+
| 7369 | SMITH | 7902 |
| 7499 | ALLEN | 7698 |
| 7521 | WARD | 7698 |
| 7566 | JONES | 7839 |
| 7654 | MARTIN | 7698 |
| 7698 | BLAKE | 7839 |
| 7782 | CLARK | 7839 |
| 7788 | SCOTT | 7566 |
| 7839 | KING | NULL |
| 7844 | TURNER | 7698 |
| 7876 | ADAMS | 7788 |
| 7900 | JAMES | 7698 |
| 7902 | FORD | 7566 |
| 7934 | MILLER | 7782 |
+——-+——–+——+
emp b 领导表
+——-+——–+——+
| empno | ename | mgr |
+——-+——–+——+
| 7369 | SMITH | 7902 |
| 7499 | ALLEN | 7698 |
| 7521 | WARD | 7698 |
| 7566 | JONES | 7839 |
| 7654 | MARTIN | 7698 |
| 7698 | BLAKE | 7839 |
| 7782 | CLARK | 7839 |
| 7788 | SCOTT | 7566 |
| 7839 | KING | NULL |
| 7844 | TURNER | 7698 |
| 7876 | ADAMS | 7788 |
| 7900 | JAMES | 7698 |
| 7902 | FORD | 7566 |
| 7934 | MILLER | 7782 |
+——-+——–+——+员工的领导编号=领导的员工编号
select a.ename as '员工名',b.ename as '领导名' from emp a inner join emp b on a.mgr=b.empno;
外连接
什么是外连接?和内连接有什么区别?
内连接:假设A和B进行连接,使用内连接,凡是A和B能匹配上的记录都能查询出来。AB两张表没有主副之分,平等。
外连接:A和B进行连接,外连接,AB两张表中有一张是主表,另一张是副表。主要查询主表中的数据,捎带查询副表,当副表中的数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。
外连接的分类?
左外连接(左连接) :表示左边的这张表是主表。
右外连接(右连接):表示右边的这张表是主表。左连接有右连接的写法,右连接也会有对应的左连接的写法。
?找出每个员工的上级领导
内连接:select a.ename as '员工',b.ename as '领导' from emp a inner join emp b on a.mgr=b.empno ;
外连接(左外):select a.ename as '员工',b.ename as '领导' from emp a left outer join emp b on a.mgr=b.empno;
外连接(右外):select a.ename as '员工',b.ename as '领导' from emp b right outer join emp a on a.mgr=b.empno;//outer可以省略
外连接最中的特点就是:主表的数据无条件全部查询出来
?找出那个部门没有员工

select e.*,d.* from emp e right outer join dept d on e.deptno = d.deptno where e.empno is null;



